
"Surveys" sounds niche and not what I need
Totally fair, but many research tasks and experiments can be designed as survey-like interactions.


What is E[🦜]?
When asked what Expected Parrot does, I usually say:
Our open-source Python package EDSL lets you simulate surveys and experiments with AI agents and large language models.
I add “experiments” because “surveys” does sound niche, and I want to convey that there are many things you can do besides simulating traditional surveys. I mention “AI agents” because EDSL lets you design personas for language models to use in answering your surveys. But there are lots of use cases where AI agents are not needed at all.
So what are these other use cases?
Below are quick overviews of some of these other use cases. Really, any time that it would be helpful to have a language model answer some question and get the response back in a formatted dataset, you can probably use EDSL.
If you have a use case that you don’t think squares with any of these, or my explanation is lacking, please let me know! I love creating demo notebooks.
Simulating games & other agent interactions
You can simulate interactions between agents as a series of one-question surveys sent back and forth between agents, with the context of prior questions and answers automatically included at each step. You can also do this with multiple agents to simulate rounds of games with complicated instructions and information about other agents’ choices/actions. Our conversation module provides built-in methods for setting this up with example code for interactions and negotiations:

Join our Discord to connect with researchers who are using EDSL for simulating games and can share more examples!
Qualitative analysis via free text responses
When conducting exploratory research on complex topics, free text questions allow for rich, nuanced responses. For example, we could use a model to review and comment on some content (note that we can use a “scenario” placeholder in the question in order to re-use it with different content):

After generating qualitative responses, we can also use EDSL to extract and quantify themes that appear in the responses.
Quantifying qualitative data
One way to do this:
Use a free text question prompting a model to provide some qualitative content.
Then run a question prompting a model to review each free text response and identify the themes in it (see data labeling examples above).
Then run a question prompting a model to turn the set of all themes into a non-duplicative summary list of themes (i.e., create a new short list that covers all the individually-identified themes).
Use the summary list as options for a checkbox question prompting a model to review each free text response (again) and select all the themes that appear in it.
Use built-in methods for quantifying the checkbox results.
See an example of this (quantifying course evaluations).
We also have a new module for automatically extracting and quantifying themes in qualitative content. Please send me a message to request access!
Data labeling & cleaning
I recently wrote about this use case which entails designing surveys about your data, where you use a language model to answer questions about each data point in a dataset. For example, we could choose a different question type for the above question and use it for a large collection of texts all at once:

EDSL will return the responses from the model in a formatted dataset that is specified by the types of questions that you use—free text, linear scale, numerical, matrix, etc. You can also use multiple models at once to compare performance (see the next example below), and use methods for auto-importing data from many different sources (images, docs, CSVs, PDFs, tables, etc.).
We have lots of notebooks for this use case that you can download and modify for your own content and purposes.
Comparing model performance
If you’re doing research on language models themselves (as opposed to using them to assist your research, such as with data labeling tasks), you can use EDSL to simplify the task of gathering data on multiple models at once in a convenient dataset.
EDSL works with many popular service providers, including Anthropic, Azure, Bedrock, Deep Infra, DeepSeek, Google, Groq, Mistral, Ollama, OpenAI, Perplexity, Together and Xai. You can check model availability, token rates and performance on test questions here:

To collect responses from multiple models at once we simply add them all to a survey when we run it:

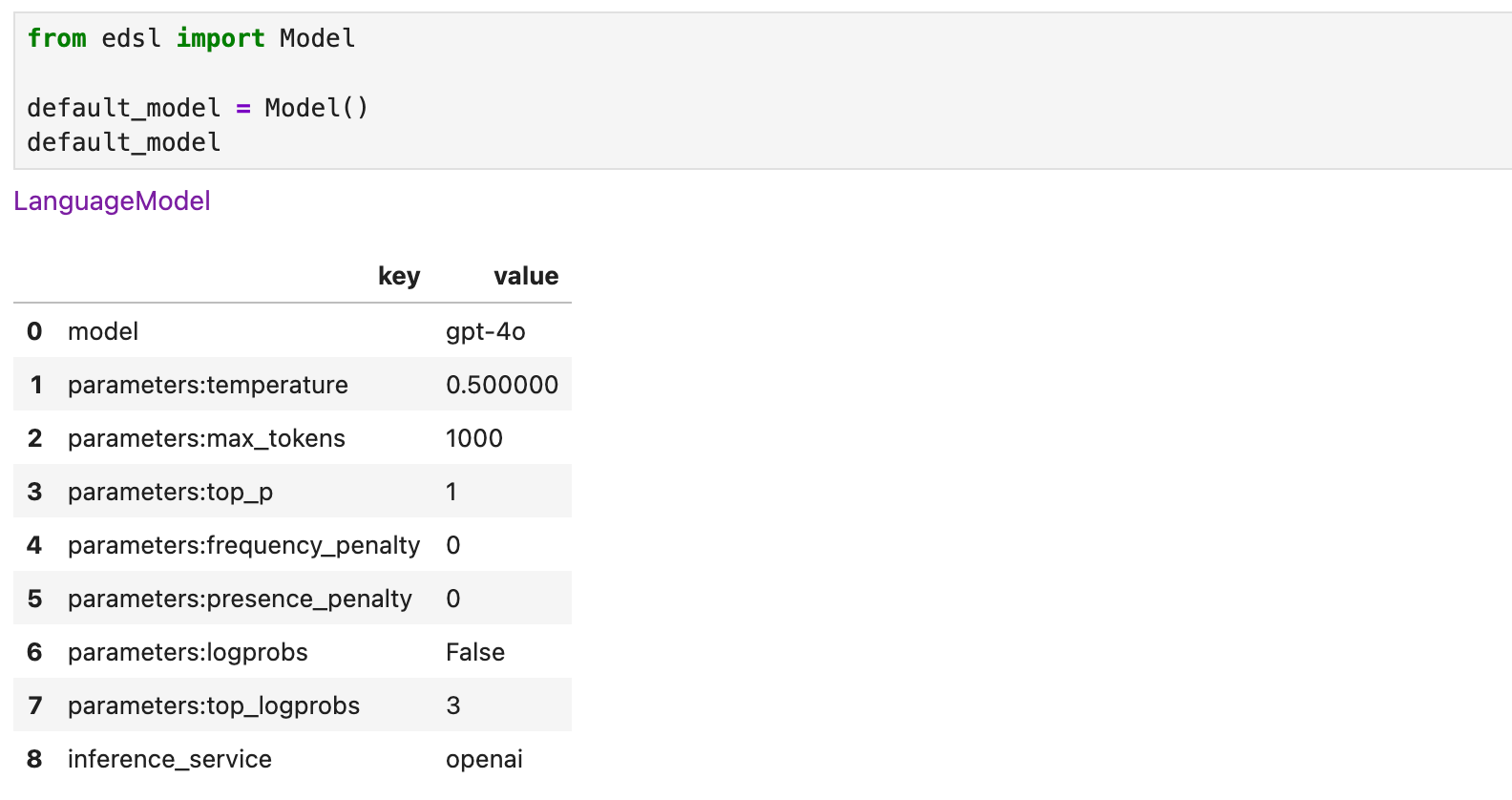
This produces a dataset of results containing responses for each model that was used, with columns for all of the components of the survey job, including the model parameters that you can specify. If you don’t specify a model to use with a survey the default model is used; you can inspect the default params:
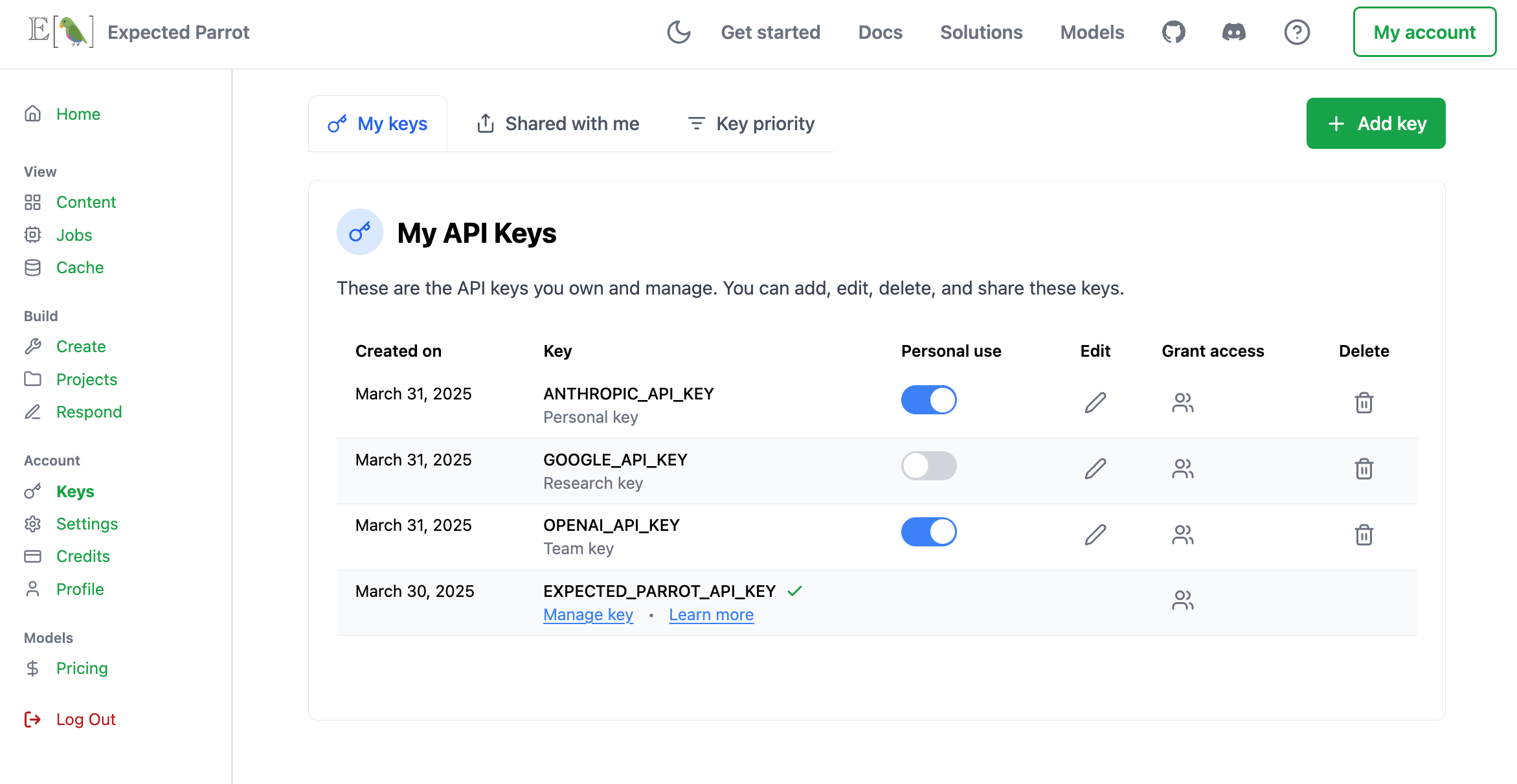
When you add models to a survey you can choose whether to use your own API keys for models or use an Expected Parrot key to access all models at once. You can also mix and match keys, share access with team members and set usage limits (learn more):
You can simulate traditional surveys too
Finally, here’s a use case that is most likely envisioned by my description of the tools:
Simulate a traditional survey with human respondents represented by AI agents
For example, here’s a quick survey where I am personally qualified to report that the model’s response is pretty accurate:
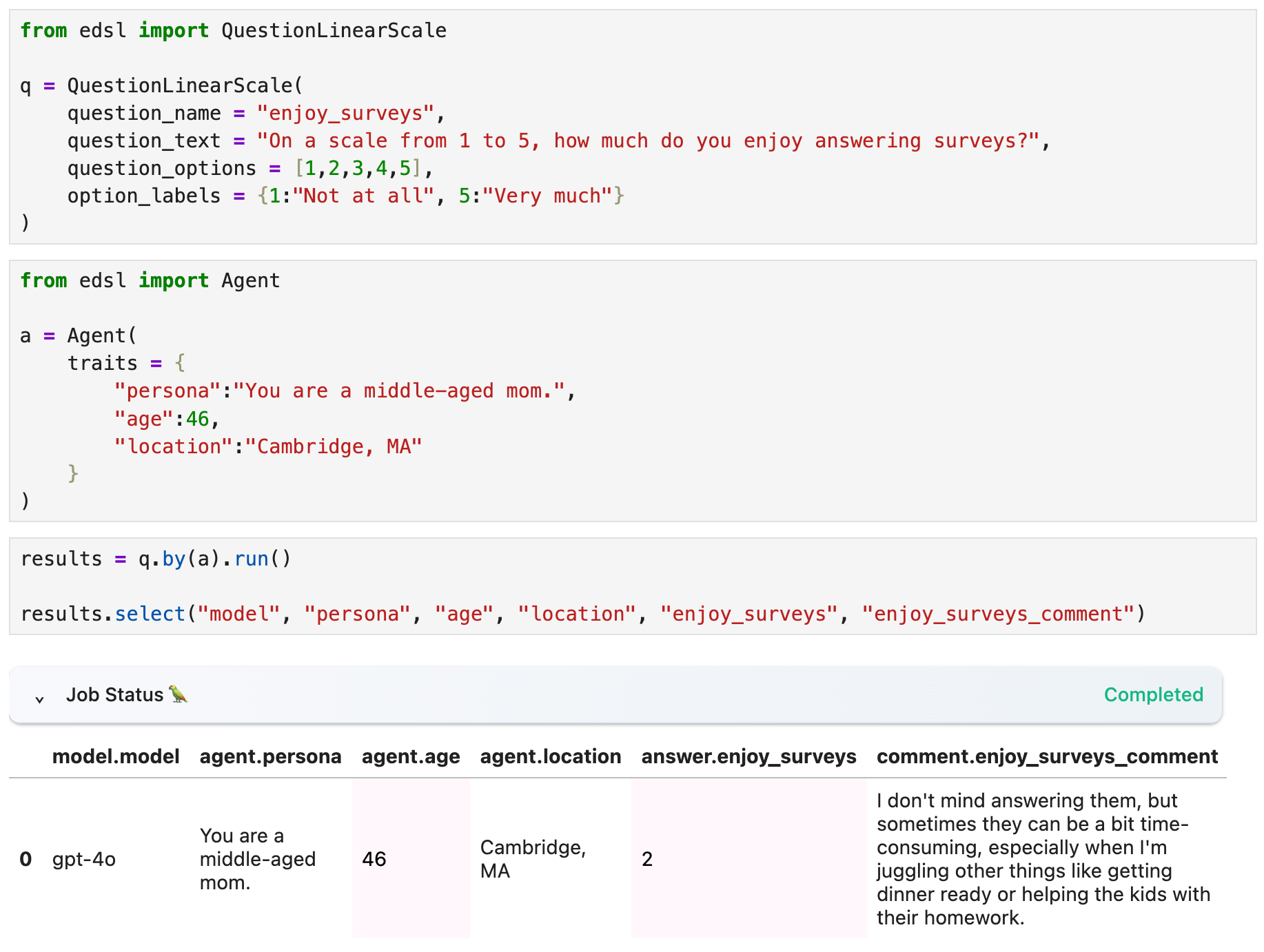
I’ve shared the results publicly, so anyone can view them at Coop, replicate the results for free, and re-use the survey however you want.
Launch hybrid human/AI surveys
If I want to add human responses to the mix (or I don’t want to write code), our no-code Survey Builder interface lets you design and run EDSL surveys with AI agents and send a web-based version of the survey to human respondents. Here I recreate the above survey:

I’ve also made the Coop page public, so anyone can view and re-use it.
Feel free to add your response!

 | A guest post by
|