
How to use a language model to label your data
I have a large collection of [texts, images, PDFs, CSVs, tables, transcripts ... ] that I need to [sort, tag, extract, clean, analyze, synthesize, summarize ... ].


“Data labeling” is an unexciting term for a very common task. We’re referring quite generally to any situation where you have a collection of data that needs to be analyzed or restructured for some purpose—e.g., you want to extract information from texts, classify images, sort or summarize content, reformat data, identify errors, etc.
Whether or not your ultimate task or research goal has anything to do with language models, using a model to perform data labeling tasks can be very helpful to your process.
How does it work?
Using a language model to perform a data labeling task typically consists of:
Sending your data to a model
Giving the model instructions on how to label (analyze, restructure, etc.) the data
Getting back labeled data you can use
Benefits of using a language model
If you can get it working, this method can provide you:
Substantial cost & time savings. Many data labeling tasks require a lot of human effort that may not be available. Using a model can not only save you time and money, it can unlock new projects that you wouldn’t have been able to complete without automated assistance.
Superhuman consistency of results. A model will tirelessly work through your large datasets!
Reproducibility. You can build—and iterate on—processes that are easily reproducible. And the task gets easier to set up as models get better.
Some do’s and don’ts
It can be tempting to try to do it all in one go. Context windows are big; if your dataset fits, you can always write a smart prompt, send all your data and hope for the best. You might also want to ask all your questions at once to save on tokens.
But you may have better luck if you break the task into steps. Rather than prompting a model review your entire dataset at once, instructing a model to evaluate data individually, and one question at a time, may produce more consistent and complete results.
Challenges of step-wise labeling
Challenges of this approach—evaluating a dataset piece by piece instead of collectively—include figuring out how to avoid or automate repetitive steps and collecting all the outputs (individual labeled data and responses) in an organized way.
This is where we think EDSL can provide a lot of value.
Why EDSL
EDSL is an open-source Python package for simulating surveys with AI agents and language models. It is designed for researchers who want to conduct in-depth experiments with many agents and models and easily replicate results, while avoiding one-off software development work required to connect with different service providers.
A key feature of EDSL is that survey results are returned to you as specified datasets, where the format is determined by the question types that you use—free text, multiple choice, linear scale, matrix, dictionary, etc. This makes data labeling an ideal use case, where you create questions about your individual data and get back a formatted dataset that is determined by your question types and instructions. In a nutshell:
Design the task as a survey about your data
Here’s a quick example of how it works (you can view and download it in a notebook):
Import your data. EDSL provides methods for auto-importing data from many different sources (CSV, PNG, PDF, tables, texts, etc.) and creating “scenarios” for the data in order to add it to questions. Here we create a scenario for a Japanese print and provide a dictionary key (“image”) that we’ll use to add the print to questions:


Construct questions about your data. We can choose from many common question types based on the format of the response that we want to get back from the model (free text, multiple choice, linear scale, matrix, etc.). Here we construct some simple questions about the print, using a placeholder for the key that we specified:

Combine the questions in a survey. We can also add skip/stop rules and other logic to conduct multi-step processes:

Send the survey to a language model to generate the responses. We can also use multiple models at once to compare responses in the same dataset of results:

Get a formatted dataset of results. We can access the results at Coop:
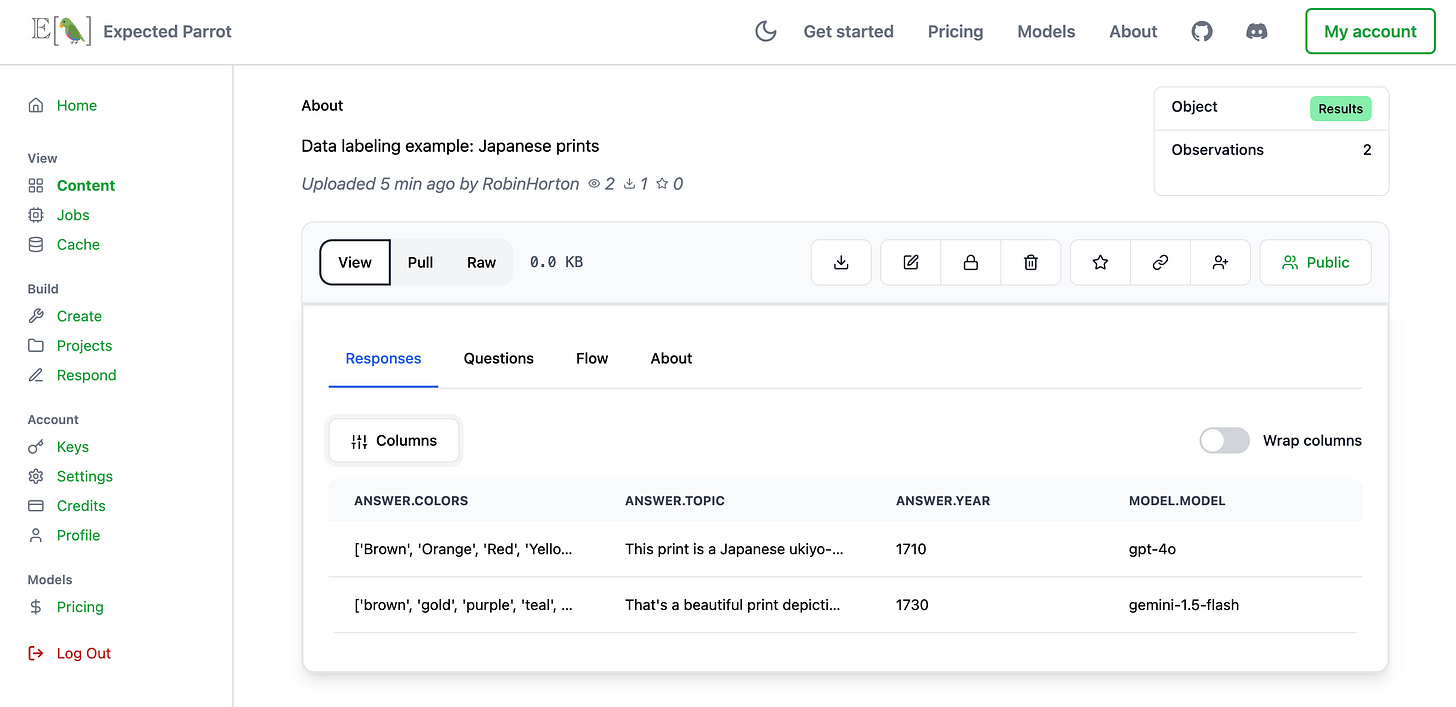
Or use built-in methods for analyzing and exporting results from your workspace:









You can view and download this example in a notebook. The code is readily modifiable for your own content and purposes.
More examples
Here are some more demo notebooks for data labeling tasks—please let us know if you have any questions!
Preparing an expense report
We prompt a model to review a credit card statement, extract expenses, identify reimburseables and prepare an expense report memo: notebookAnalyzing course evaluations
We use a series of questions to identify, standardize and then quantify themes in a set of course evaluations: notebookTriaging customer service tickets
We prompt a model to sort a collection of messages from users: notebookAgent-specific tasks
We have different agent personas label specific subsets of data relevant to each persona: notebookSummarizing & quantifying themes in a set of transcripts
This is similar to the course evaluations example above: notebook
Have a different use case for a demo notebook? Please let us know and we’ll be happy to help create it for you!
 | A guest post by
|