
'Whit' Diffie Erasure!
Why human-provided structure improves AI answers to research questions, with examples.


Using LLMs to structure unstructured data is arguably the killer application because it allows us to answer questions that otherwise would have taken a ton of time (I’ve done some teaching on this topic). In this blog post, I want to give an example of answering a data-driven question two ways: (1) asking the question directly to an LLM and (2) structuring the data first and then aggregating. While (1) is faster, (2) has some real advantages.
Question: How many Turing Award winners graduated from MIT?
Say I want to know how many Turing Award winners received a degree from MIT. This is a very answerable question, but there very likely isn’t an exact dataset I need with an “mit_degree” boolean field. I’ll need to construct it.
In the distant past (say, 3 years ago), I could have taken Wikipedia bios and maybe done a regular expression search for “MIT”—though given how many winners are affiliated with MIT but did not graduate, this would be error-prone. Ultimately, I’d probably have to review by hand. Now, of course, we can use AI.
First, I’ll show approaches that don’t really work (with Claude) and that do work (with o3) but also a method that works with less sophisticated models and that has a number of other advantages as an answering approach.
Claude gives an MIT ‘vibes’ answer
The Claude answer definitely finds some related info but includes people with MIT connections but not actual degrees. This is probably because every time someone wins a big award, universities try to establish some connection (“Herb Simon once ate in our cafeteria!”). There is also a counting effort, but garbage-in, garbage out.

o3 seemingly nails it
I asked OpenAI’s o3 “How many Turing award winners received their PhD from MIT?” and then asked about degrees generally. Watching the reasoning traces as they flashed on the screen, it seemed to do something sensible and probably what one of us would do if given the task—it got a list and then kept doing web searches until it found the relevant information, almost all from Wikipedia:
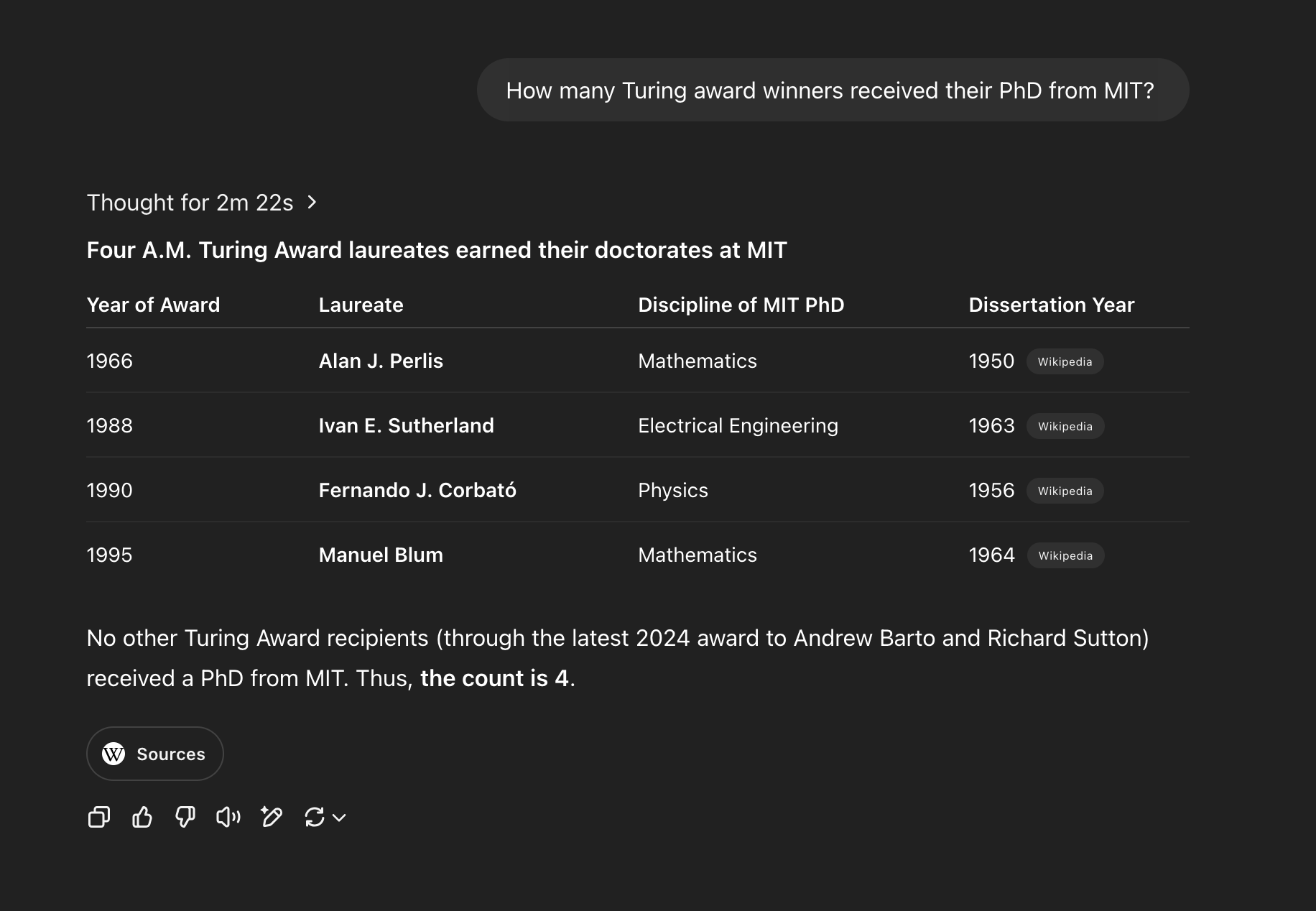
As far as I can tell, this is correct. But this was PhDs—let me instead do graduate degrees, which is what I mean to ask:
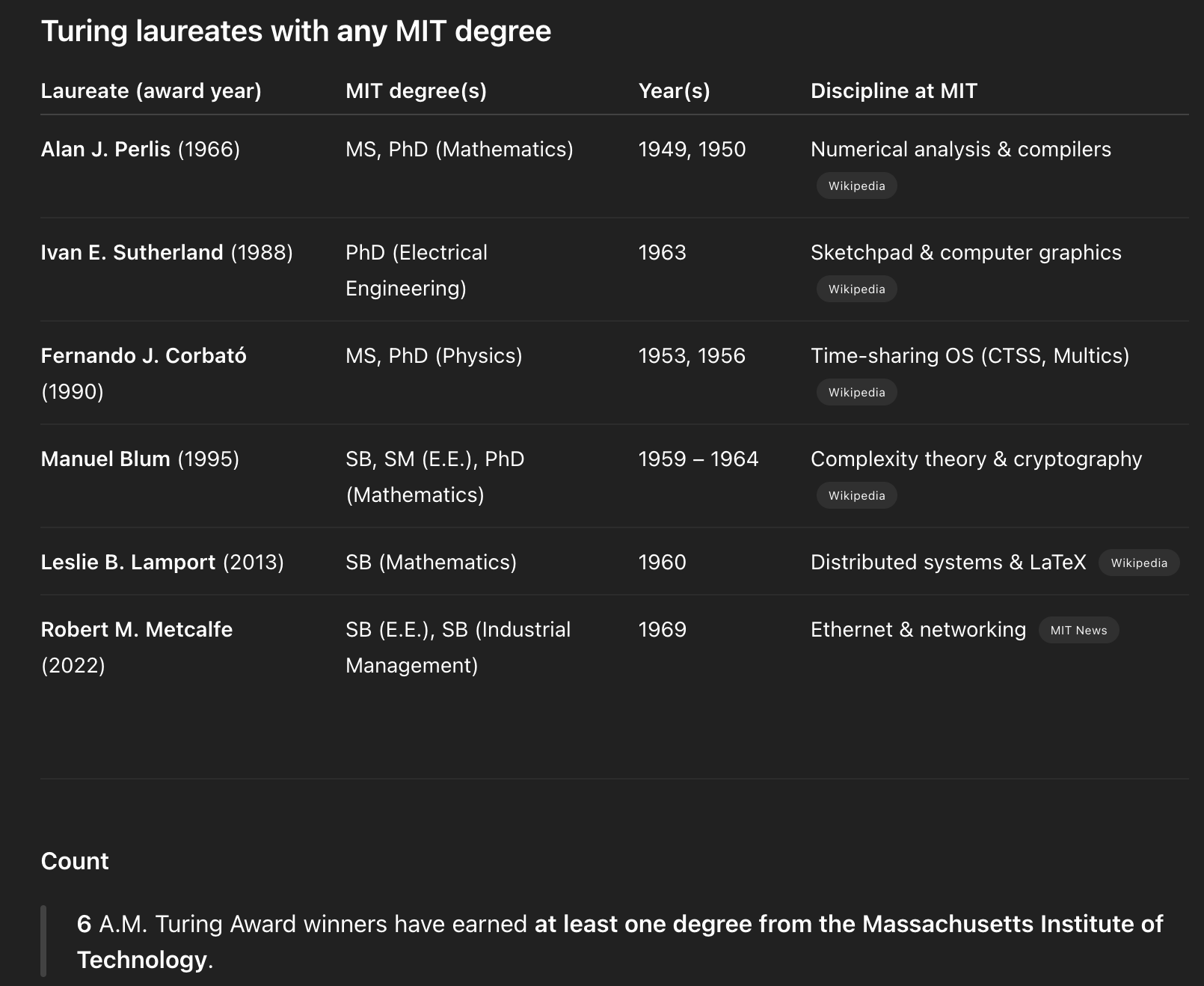
Ok, 6.
But even o3’s answer has some problems
The procedure with which this answer was obtained is opaque.
I don’t really know the process by which these determinations were made.
I don’t know if any of these are hallucinations (and I can’t easily try it with other models) or omissions.
If someone wanted to reproduce my analysis, they would have to re-run this (rather expensive) inference (2m 22s).
And what if my dataset were *a lot* bigger and not publicly accessible. There are only a fairly small number of Turing winners and the list can be found in numerous places. What if I want to do something similar but with non-public data of much larger scale—say look for who graduated from MIT from my 10,000 employees in a CSV sheet?
The E[🦜] Approach
First, the data on winners is easy to get, already arranged in a nice table at Wikipedia:
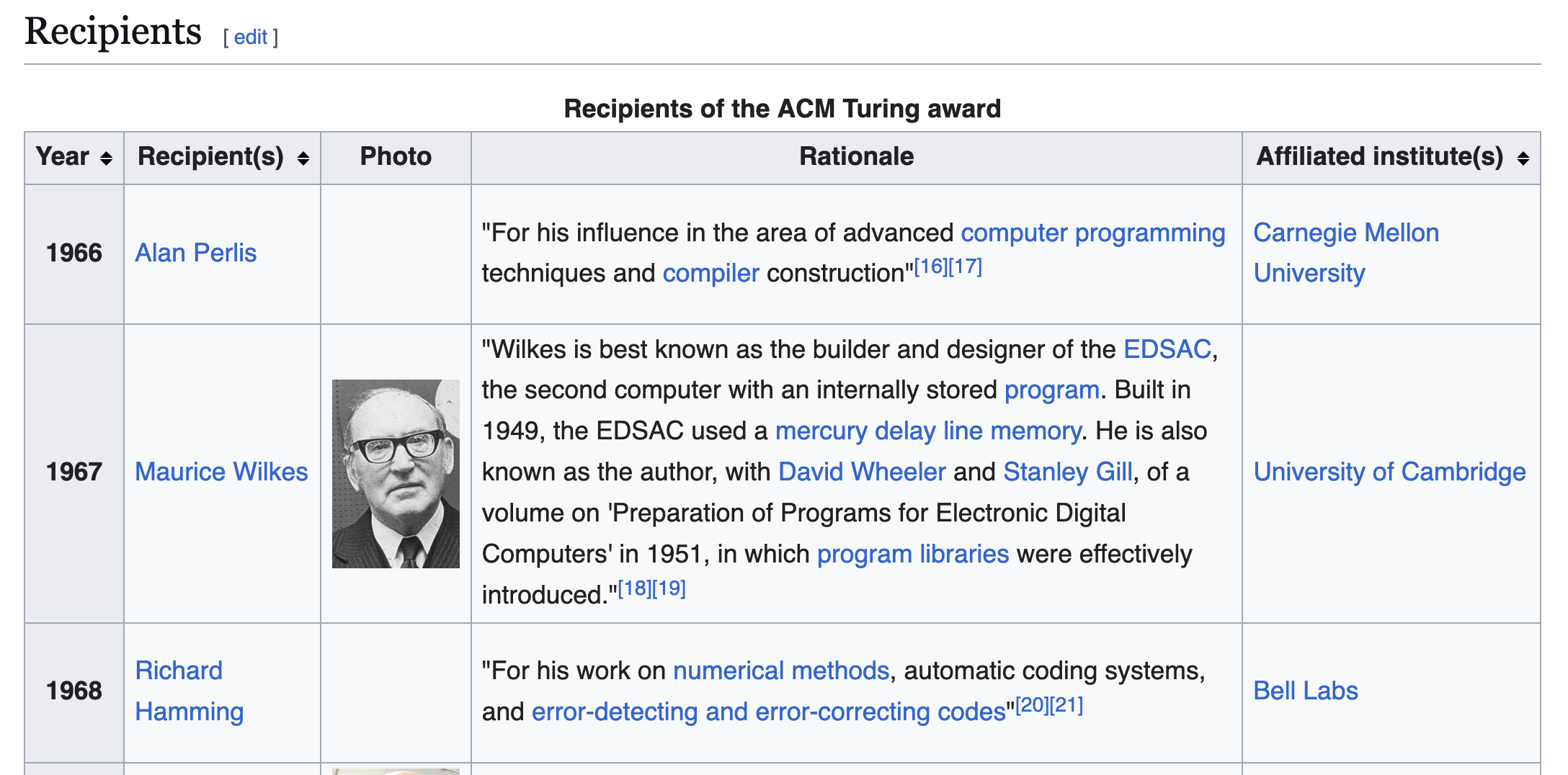
To actually extract this, EDSL (Expected Parrot Domain Specific Language) has some tools for working with Wikipedia data. The basic idea is turn it into a “ScenarioList” which is, well, a list of Scenarios for a language model to assess in some way.

The data is puled down using “from_source” method. EDSL uses a fluent interface throughout and so we can chain together methods. In particular, the keys need to be valid python identifiers, which is what that “give_valid_names()” function does. There is also an “augment_with_wikipedia” function that can get get more data about a particular search query—-in this case, the prize winner.
Here is what one entry looks like:
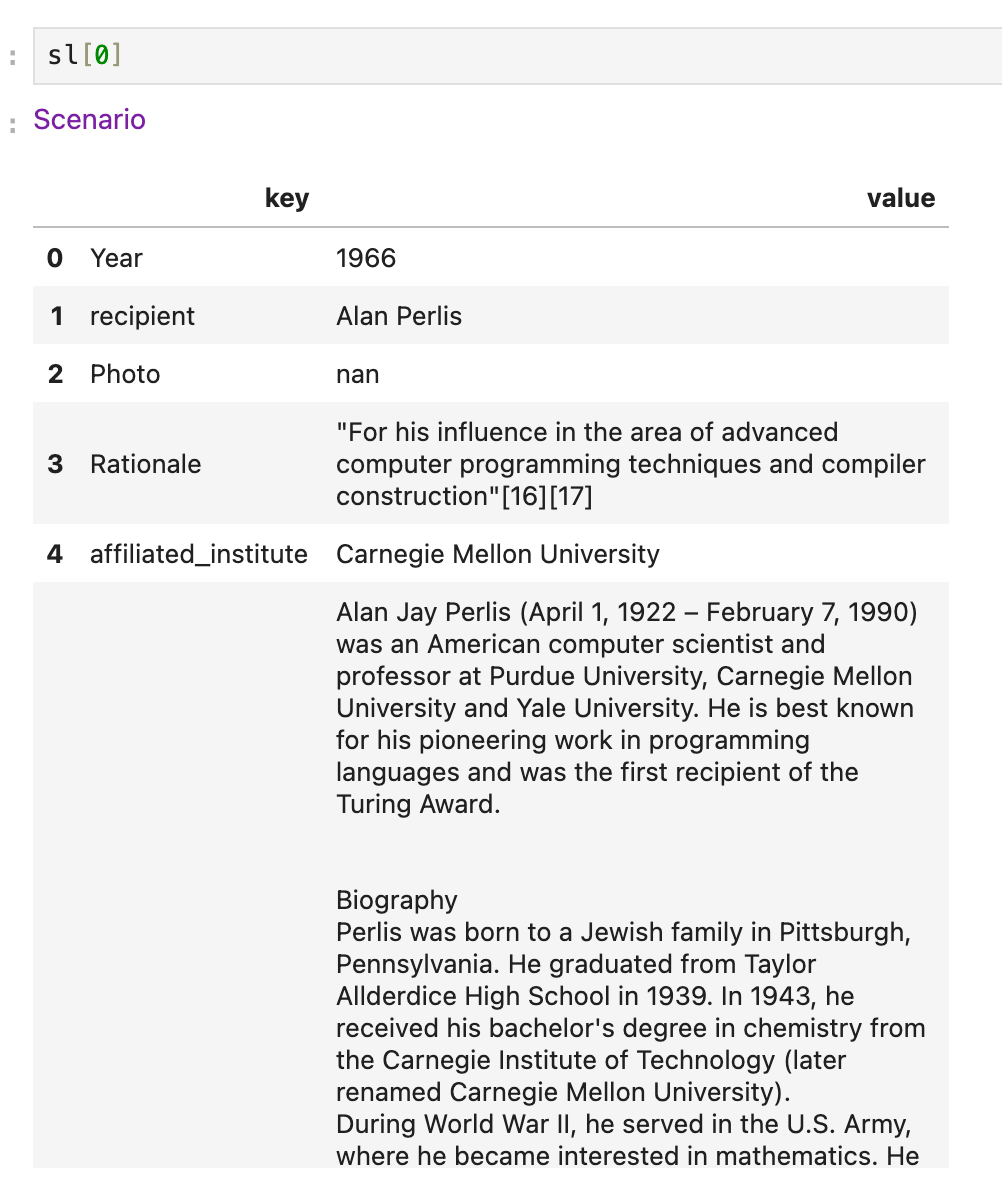
Note that I have a field that has the full biography from Wikipedia. I can then use that to ask a question: Did this person receive a degree from MIT? For this, we use a yes-no question type. Note the use of a jinja2 templating syntax:

The last line uses a fluent interface to combine this question with the scenario list and then “run” it with a language model. (The current default model in EDSL is gpt-4o; you can easily specify a different model, or run it with several models at once to compare responses.) We can see that answering question takes about 3 cents’ worth of tokens:
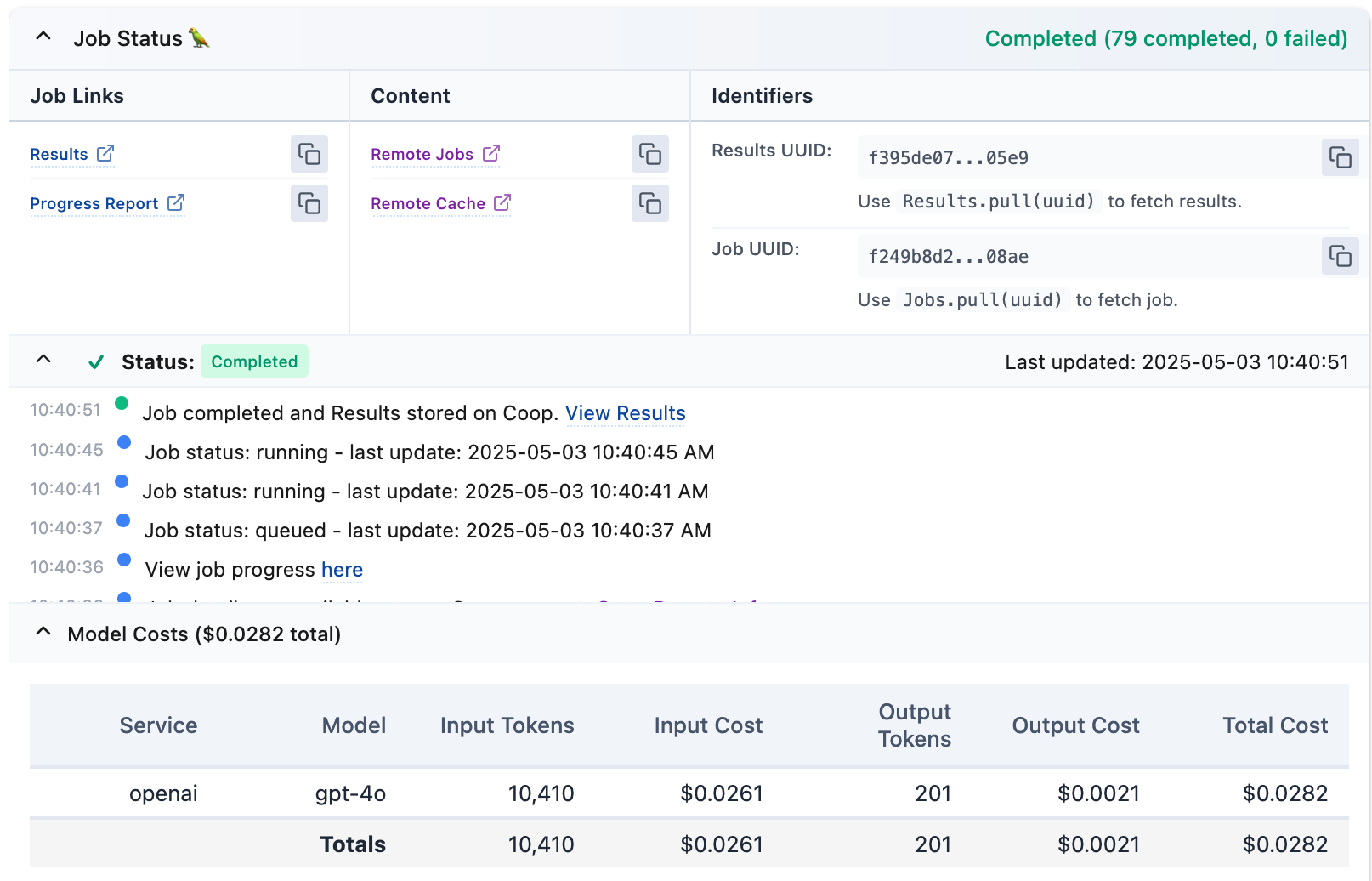
If I—or anyone else—were to run it again, the responses would be returned at no cost, as they have been “cached” at E[P]. With our results object, we can now tally up the results:
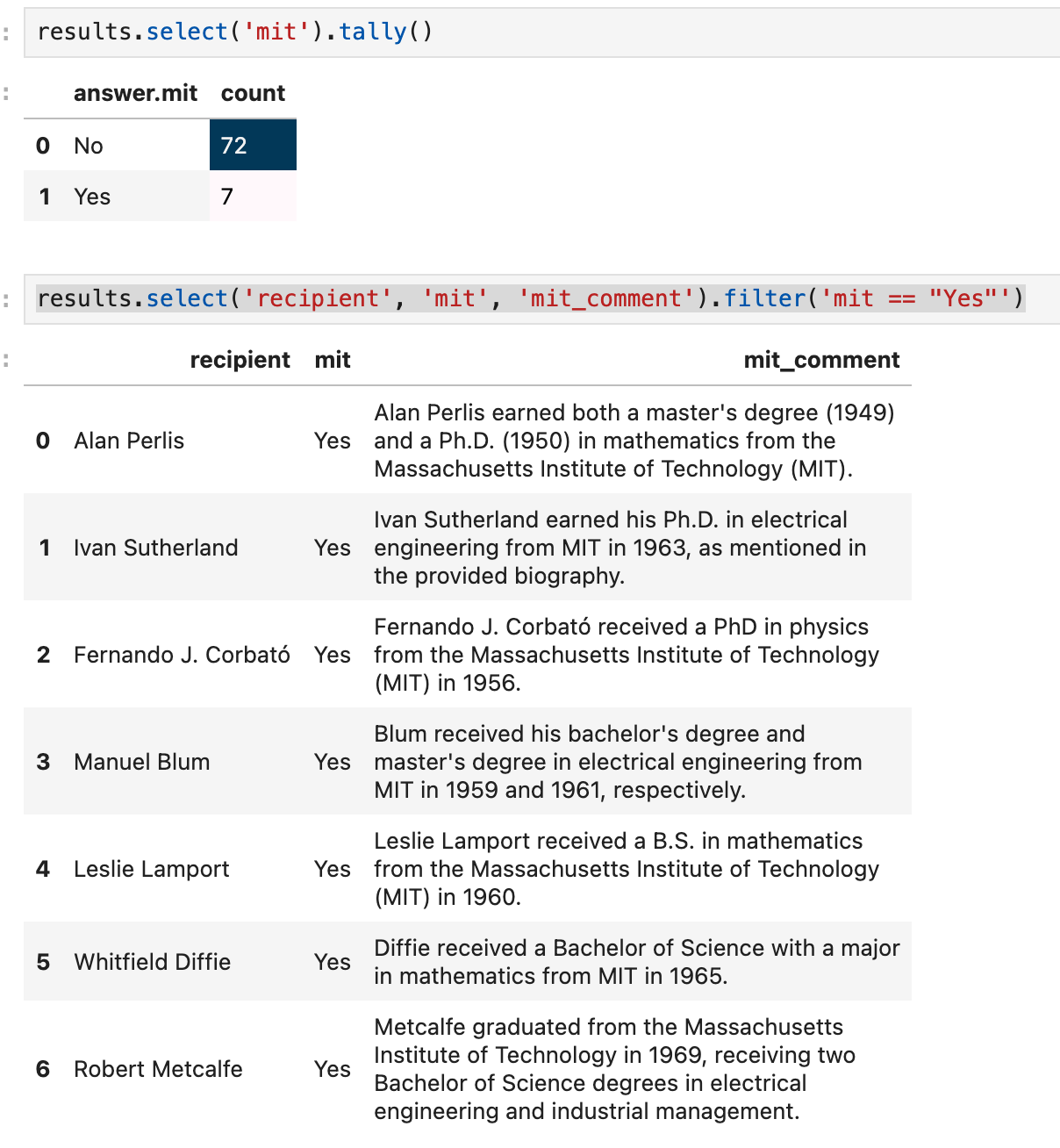
Oh, wow! But wait—boy genius o3 is wrong!
Note that o3 said 6, but the EDSL approach got us 7. NB: This wasn’t a big set-up to show our tools work better. I just noticed this as I was working it out. What’s going on? Forgetting someone?

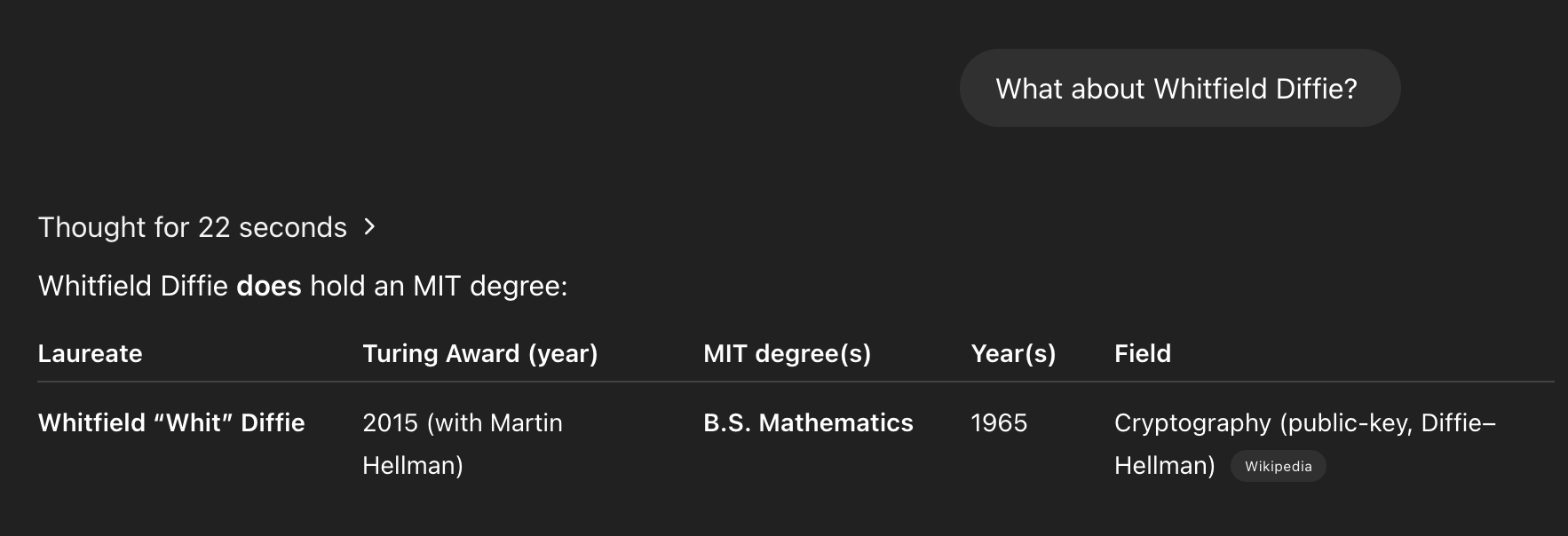
Turning the knife:

I'm wondering about a hybrid approach. What happens if you take the data you downloaded, paste it into the chat interface, and instruct 03 (or gemini) to run through row by row?