
Show prompts, please!
EDSL makes it easy to tinker with prompts, compare responses from different language models, and replicate experiments by automatically storing all your prompts, responses and code to reproduce them.


Reproducibility ↔ Visibility
Whenever you run an experiment, you want to write down your steps in such a way that someone could replicate your work without much effort. When you’re working with LLMs, this means showing—and therefore also knowing—exactly what prompts were sent to which model. That sounds pretty obvious and comparatively easy to pull off when your experiment is essentially a bunch of computer code that you can simply post on the internet.
But, alas! Models get replaced, requirements for connecting to them change, and it costs money to resend API calls to them. Even if someone eagerly wants to reproduce your work, they may by stymied by tier limits when creating their own accounts with relevant service providers.
Add to this the fact that, depending on the tools used to run your experiment, the precise details of your prompts and API calls may be difficult or impossible to ascertain, making it hard to know whether you are actually repeating your steps.
These issues may render your experimental code a bit of a relic. What’s needed to help prevent this are:
Accessible copies of your prompts and responses, so anyone can work with them
Evidence of the way your responses were generated (which model, what time, etc.), especially if they can no longer be regenerated
Code that is easily—or automatically—updated to work with current models and requirements, and that can be extended to facilitate follow-on work
These to-do’s are all straightforward to accomplish using EDSL, our open-source Python package for simulating surveys and experiments with LLMs, together with Coop, our integrated platform for creating, sharing and replicating LLM-based research. Below I show some features of EDSL and Coop for crossing each of the above tasks off the list. Please send us questions about any of them!
EDSL results are standardized datasets
When you run a survey in EDSL, the LLM responses are returned to you in a formatted dataset of results that is specified by the question types that you used (free text, multiple choice, numerical, matrix, etc.). The results automatically include (many!) columns of information about all the details of the survey, including:
Question texts and types
Agents and data used with the survey
User and system prompts
Model names, temperatures and other parameters
Survey rules and logic applied
Raw and formatted answers
Tokens consumed
Costs incurred
Timestamps
and more
There is no need to perform any post-survey data cleaning to extract this information from raw responses—it is all done automatically.
Share verified results privately or publicly at Coop
If you run your survey at the Expected Parrot server, the results are automatically added to your Coop account, where you can share them privately or publicly, or simply store them for free. A green checkmark at your dashboard verifies to anyone with access to your results that they were generated in this way:
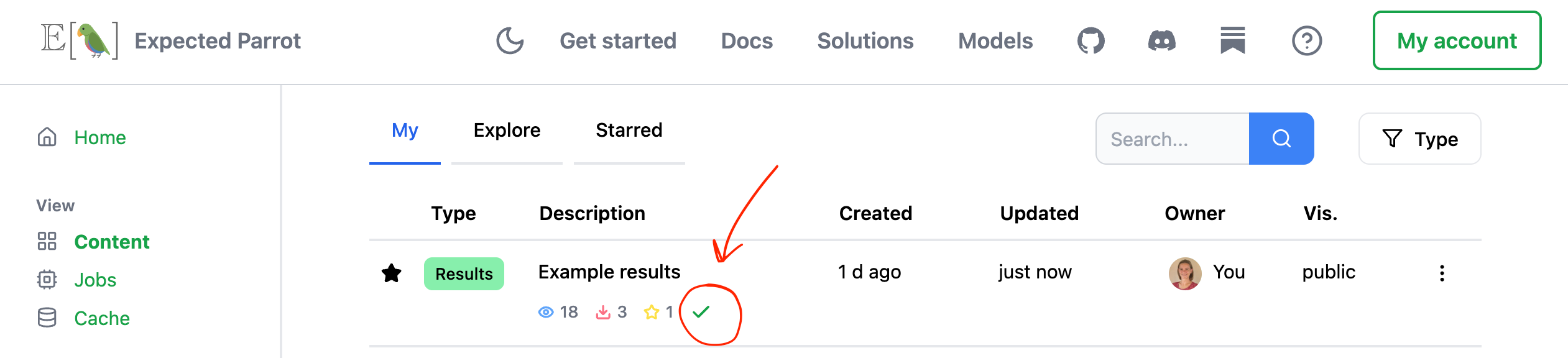
The prompts and responses are also automatically added to your own cache and a universal remote cache, so that anyone who reruns your survey can retrieve them—at no cost.
EDSL automatically stores your prompts and responses from LLMs, so you never have to worry about losing track of them or verifying how you generated them
Rerun your code with any available models
EDSL works with many popular language models. An important feature of the package is that you can pick and choose models to use with your surveys without having to do any of the high-touch software dev work needed to make API calls to various service providers. It works the same way with all available models.
For example, to run a survey with models from Anthropic, Google and OpenAI all at once we simply add them to the survey by name in the exact same way:

The results that are generated will have separate rows for each set of responses by each model, with information about each model (temperature, etc., which you can specify—in the example above we use the default settings).
Learn more about working with models.
Tinkering with prompts—how do I do that?
User and system prompts are determined by (i) the contents of your questions, (ii) details of any agents you use with your survey (they are optional), and (iii) instructions for models about the questions and agents. EDSL comes with built-in methods for editing and inspecting these instructions before you launch a survey. After a survey is run, the user and system prompts for each response are stored in columns of the results.
For example, here we show the user and system prompts that are generated for a simple question and agent with default instructions, and then show how they change when we add parameters for modifying the instructions:

We can see that the default instructions for the question include (i) an instruction about how to answer the question and (ii) and an instruction to provide a comment about the answer. This instruction to provide a comment is automatically added to all question types other than free text, and can be useful for debugging issues with answers.
We can edit or omit these question instructions by specifying either or both of the optional parameters answering_instructions and question_presentation when we construct the question. Similarly, we can edit or omit the instructions in the system prompt (“You are answering questions as if you were a human. Do not break character.”) by passing an optional parameter instruction to the agent constructor. Here we demonstrate all of them at once:


Here we run the surveys with the agents to compare the responses (the results are also accessible at Coop here and here):


Code for the above examples is available to download and modify for your own purposes in this notebook at Coop.
Learn more about methods for working with prompts in our docs.
But I don’t know Python!
Several pieces of good news here:
EDSL is designed to be intuitive to anyone wanting to conduct this kind of question-and-answer LLM-based research. Advanced Python or other programming language skills are absolutely not required.
We have lots of tutorials and demo notebooks that you can download and modify for your own purposes, and we’re available for 1-1 help at many hours of the day.
You can use our GPT to generate EDSL code too.
Our no-code survey builder interface lets you launch surveys with AI agents and send web-based versions to human respondents. You can compare and export responses from your Coop dashboard, and get the underlying EDSL code to iterate on it in a notebook or share it with your team. Send us an email if you’d like a quick demo (see a quick video and read how it works):
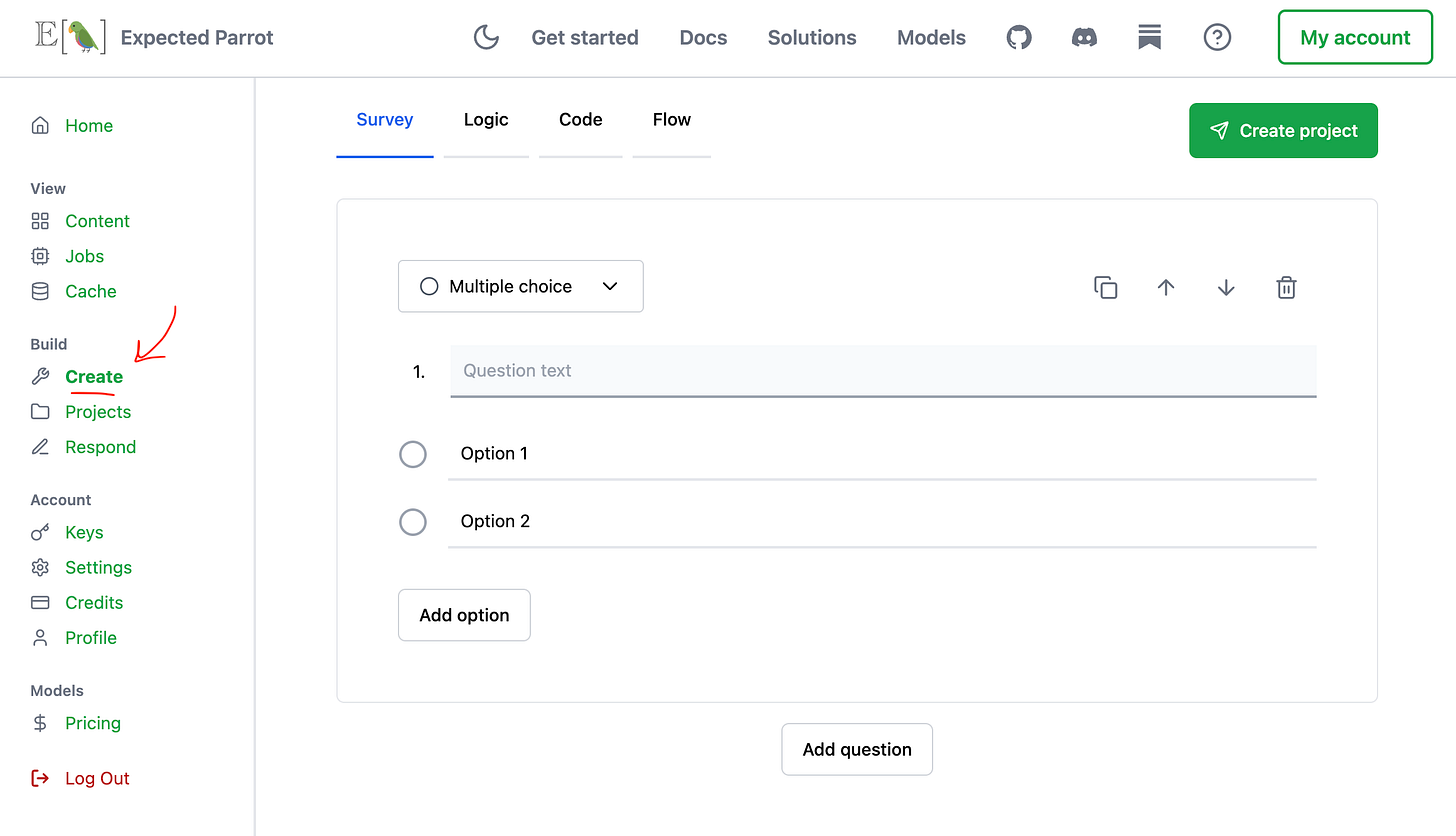
We have special features for automatically converting your existing surveys (Qualtrics, CSV, etc.) into EDSL. Send us an email to request access.


Please let us know if you need any help getting started! Feel free to post a question at our Discord or send us an email: [email protected]
 | A guest post by
|