
New features for monitoring your AI research costs
Our tools are designed to make it easy to understand and monitor your LLM usage. Learn more about our latest features for precisely tracking your costs.


Running experiments with language models can be fast and cheap. But you still want to know what all you’re spending on API calls, which models are cost-efficient for your research goals, how much it will cost to replicate or extend your work, etc. You also want to avoid making duplicative or unnecessary API calls, which can add up when you’re iterating on an experiment or working across teams.
When you run a research project with Expected Parrot it’s easy to track the details of your LLM costs and usage, using built-in methods at your workspace and at your account at Coop, a platform for creating and sharing LLM-based research. You can also replicate and share your results for free. Below we highlight some new and key features for easily and precisely tracking your costs.
Before you run an experiment…
When you’re developing an LLM research project you want to know (i) the token rates for the models that you plan to use and (ii) estimated costs for your prompts and the responses that you will receive back from the models. You also want to avoid making duplicative API calls to LLMs (resending identical prompts when you do not expect the response to change) to eliminate unnecessary $$ charges.
Checking model prices & capabilities
It can be time-consuming to gather token rates from various model service providers’ webpages, and to determine which models are capable and appropriate for your research goals and requirements (e.g., do you need a vision model for some of your prompts?).
This is why we created a model pricing and performance page where you can quickly check current token rates for models of all available service providers, and their recent performance on test questions:

The page is updated daily with details on the test questions that were used with each model. We are adding test questions that use videos! See example code for using videos with your questions.
Estimating costs
Once you’ve drafted your user and system prompts (i.e., created your questions and any agents), you can use built-in methods for estimating the costs of sending them to models (input tokens) and the costs of the responses that you will get back from the models (output tokens).
For example, here we create a simple question and then use a method for estimating input and output token costs of sending it to two different models. We can see the details also include the total credits that will be placed on hold while the survey job is running and then released when the actual cost is determined:
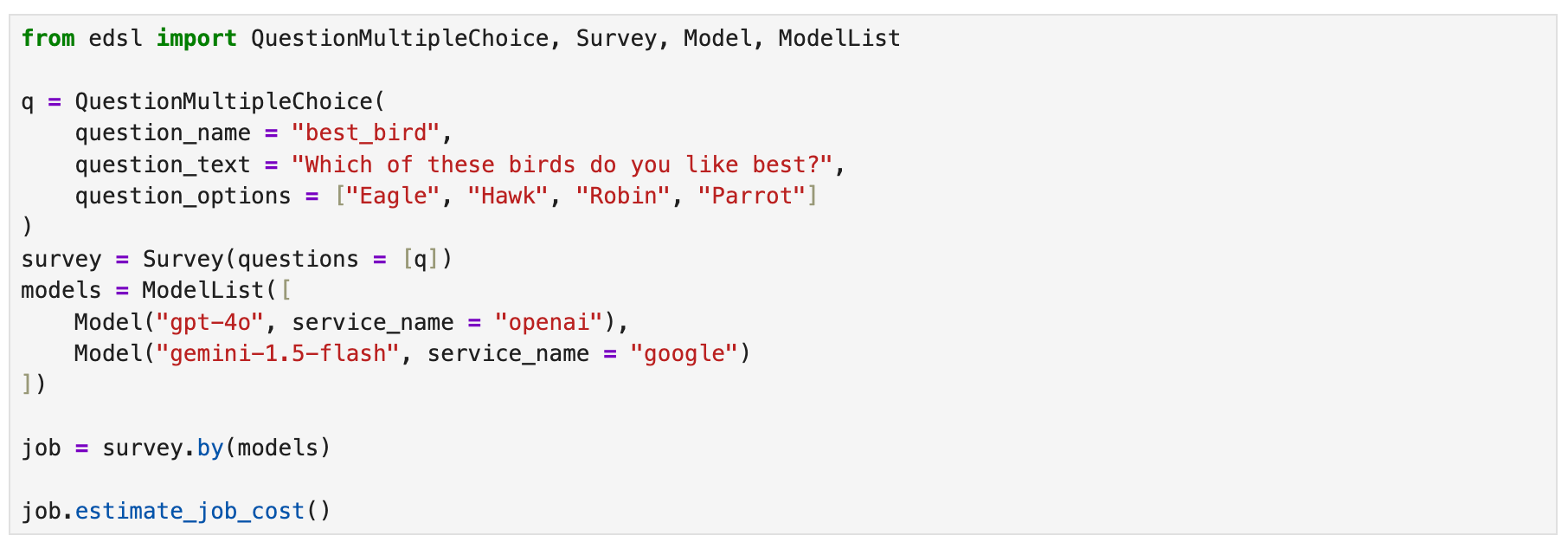

After a survey is run, we can verify the actual token costs for each model and question in the dataset of results that is generated:

You can also view token and cost details at your Coop account. Your Jobs page shows the final cost in credits of API calls to each model used with the survey:
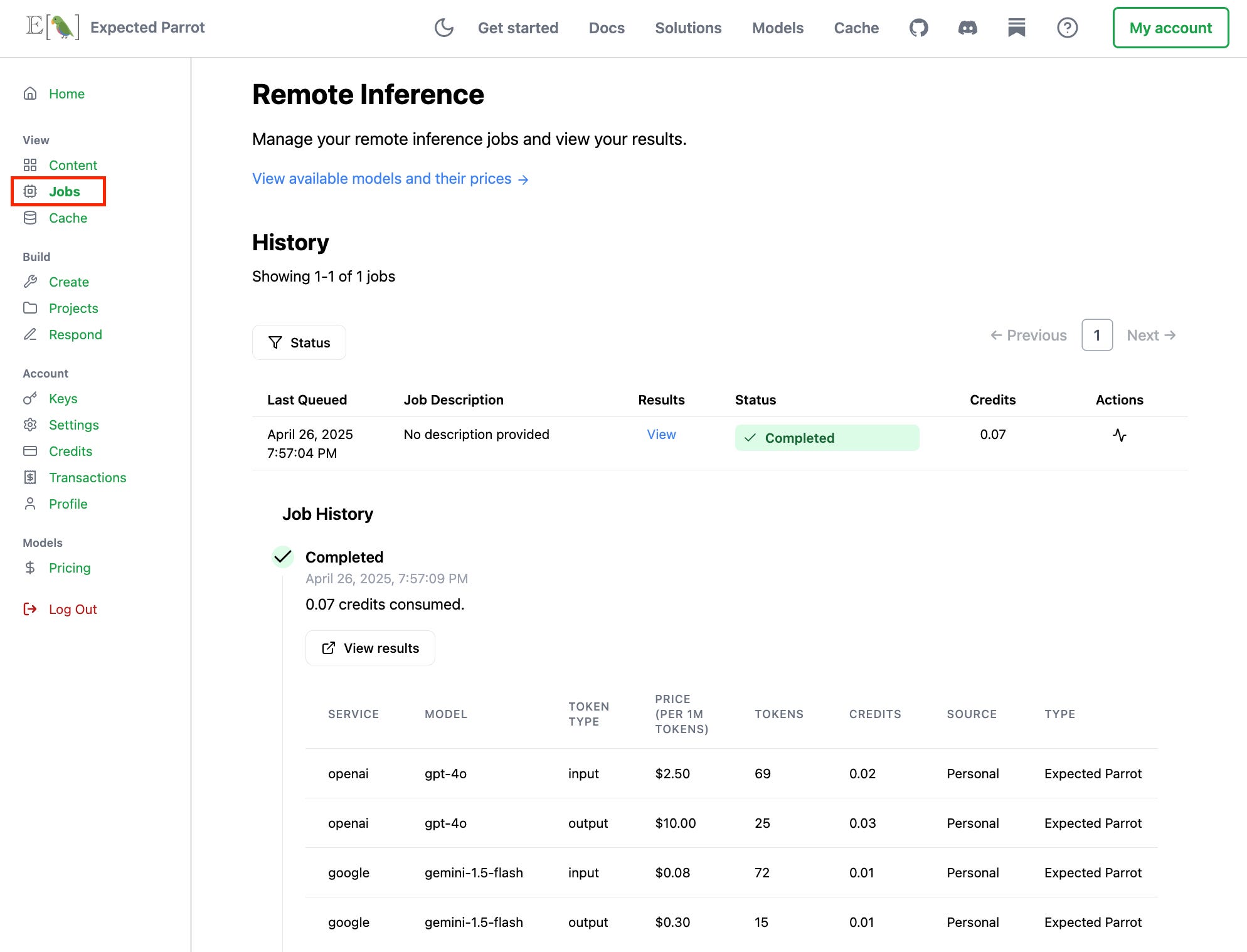
Your (new!) Transactions page shows additional details about credits placed on hold based on job cost estimates together with the final cost details:
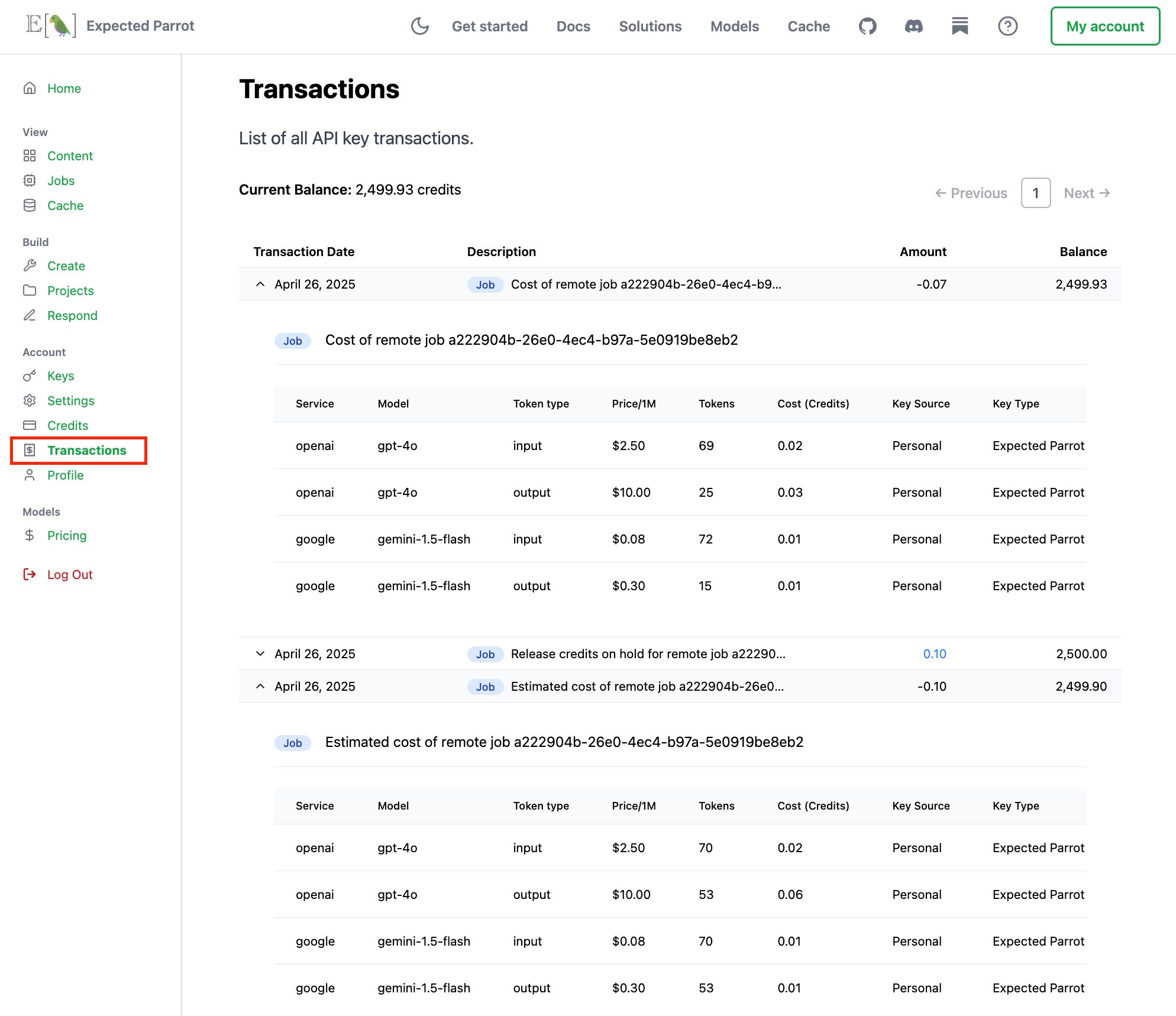
Avoiding unnecessary API calls
A key feature of EDSL is automated caching of prompts sent to models and responses received from them. This ability to retrieve responses to questions that have previously been run at no cost means that you can replicate and share any research created in EDSL for free.
For example, if we rerun the example question from above we can confirm that no additional costs are incurred:
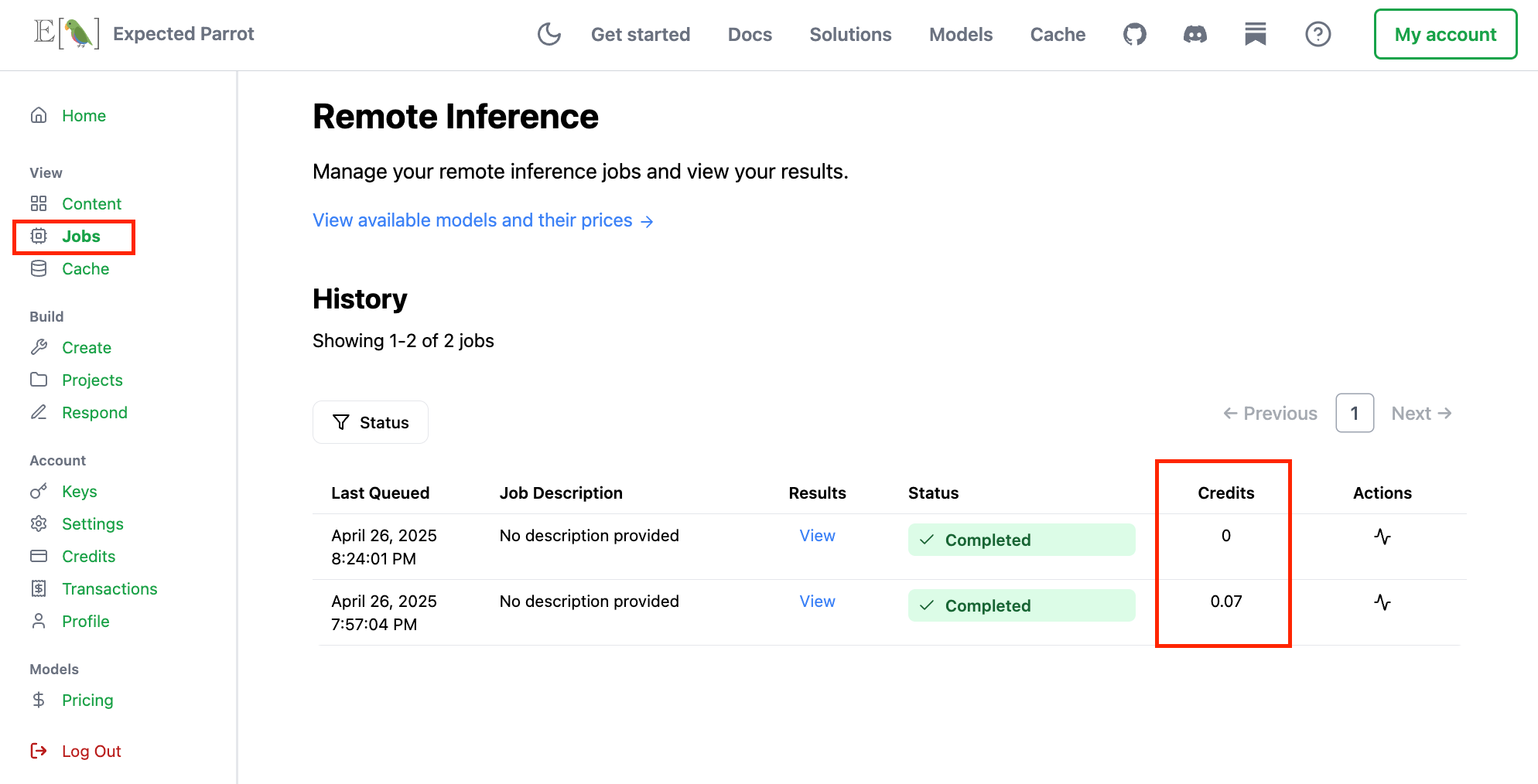
This can be useful when iterating on a research project and when publishing your research results for others to review and replicate.
 | A guest post by
|